연결 리스트

연결 리스트의 정의와 그 구성 요소를 살펴보겠습니다.
연결 리스트
연결 리스트는 포인터를 사용하여 여러 개의 노드를 연결하는 자료 구조입니다.
배열 또한 순서대로 여러 데이터를 저장할 때 사용한다는 공통점이 있습니다. 하지만 배열은 크기를 조정해야 한다는 문제점이 있습니다.
배열과 다르게, 연결 리스트는 항상 맞는 크기로 만들어지도록 설계되어 있습니다. 그래서 순차적인 데이터나 많은 양의 테이터를 정리하는데 이점을 갖고 있습니다.
노드
연결 리스트의 기본 구성 요소는 노드입니다. 노드에는 인접한 노드를 가리키는 next라는 이름의 포인터와 데이터를 가리키는 포인터가 있습니다.

연결 리스트는 head라는 이름의 포인터에서 시작하는데, Head는 리스트의 첫 번째 노드를 가리킵니다. 힙에서는 이 연결 리스트의 head만 알고 있기 때문에, head.next 혹은 head.data 등으로 노드의 내용을 찾습니다. 하지만 연결 리스트의 길이가 매우 길 경우, 계속 head 뒤에 next를 붙일 수는 없습니다. 그래서 임시 포인터를 사용하여 탐색하는 방법을 사용합니다.
노드와 크기
연결 리스트를 정의하는 클래스를 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class LinkedList <E> implements ListI<E>{
// 노드 정의
class Node<E>{
E data;
Node<E> next;
public Node(E obj){
data=obj;
next=null;
}
}
private Node<E> head;
// 노드 개수를 세는 변수
private int currentSize;
// 기본 연결리스트
public LinkedList(){
head=null;
currentsize=null;
}
}
연결 리스트의 내부 클래스에서 노드를 정의하여 다른 곳에서의 접근을 막고 있습니다.
data의 자료형은 E입니다. E(Element)는 정해지지 않은 자료형이고 이렇게 구현한 연결 리스트를 사용하면 그때 지정하겠다는 의미입니다. 그리고 next의 타입은 Node입니다. 다른 노드를 가리키는 포인터이기 때문입니다.
생성자까지 추가하여 코드를 적으면(E를 쓰지 않습니다) 노드 객체가 완성됩니다. 생성자에서는 객체를 data에 저장하고 next는 우선 null로 지정합니다. 이 노드 객체는 내부 클래스이기 때문에 연결 리스트가 아닌 다른 곳에서 접근할 수 없습니다. 외부에서 접근하기 위해 노드 객체를 만들 때와 같이 private 변수 head를 만듭니다.
노드의 개수를 세는 변수인 currentSize가 추가되어 있는데, 노드의 개수를 직접 하나씩 세는 방법보다 int 타입인 변수 currentSize를 만들어 노드의 개수를 세는 방법이 더 효율적이기 때문입니다.
노드의 개수를 직접 셀 경우, 요소가 n개면 n번 세야 합니다. 따라서, 하나씩 세는 것의 시간 복잡도는 θ(n)입니다. 하지만 currentSize라는 변수를 만들어놓고 리스트에 요소를 추가할 때마다 currentSize의 값을 늘려 놓으면, 리스트의 크기를 바로 알 수 있습니다. 이럴 경우, 시간 복잡도는 정확히 1입니다.
경계 조건
연결 리스트를 사용하기 위해 고려해야 할 경계 조건들이 있습니다.
-
자료 구조가 비어있는 경우
-
자료 구조에 단 하나의 요소가 들어있을 때
-
자료 구조의 첫 번째 요소를 제거하거나 추가할 때
-
자료 구조의 마지막 요소를 제거하거나 추가할 때
-
자료 구조의 중간 부분을 처리할 때
위의 사항들을 고려해서 연결 리스트에 사용되는 메소드들을 작성해보도록 하겠습니다.
addFirst 메소드
연결 리스트의 앞부분에 node를 추가하는 addFirst 메소드를 경계 조건을 만족하는지 확인하며 작성해보겠습니다.
새로운 node를 연결 리스트의 앞부분에 추가하는 방법은 다음과 같습니다.
- 새로운 node를 만든다.
- 새로운 node의
next가 현재head를 가리키도록 한다. head포인터가 다시 새로운 노드를 가리키도록 한다.
이 과정을 코드로 작성하면 다음과 같습니다.
1
2
3
4
5
public void addFirst(E obj){
Node<E> node = new Node<E>(obj); // 1
node.next = head; // 2
head = node; // 3
}
주의할 점은 node.next와 head를 명시하는 순서가 바뀌어서는 안됩니다. 순서가 바뀔 경우, 원래 있던 노드를 가리키는 것이 없어지기에 GC가 작동하게 됩니다.
위 코드는 5가지 경계 조건에 대하여 생각하였을 때에도 문제가 없습니다.
-
비어있는 연결 리스트인 경우,
head는null을 가리킴.node.next = null이 되어도 문제 없음 -
요소가 한 개일 경우, 주의할 점 없음
새로운 노드를 연결 리스트의 앞부분에 추가하는 메서드이므로 위와 같이 3,4,5 번째 경계 조건은 고려하지 않아도 되므로 문제가 없다는 것을 알 수 있습니다.
그리고 새로운 요소를 추가하기 위해 뒷부분을 살펴볼 필요가 없기 때문에 시간 복잡도는 1입니다.
addLast 메소드
연결 리스트의 마지막에 node를 추가하는 addLast 메소드입니다.
addLast 메소드에서는 연결 리스트의 마지막을 가리키는 임시 포인터를 사용합니다. 연결 리스트의 요소를 확인하려면 무조건 head에서 시작해야 하는데, 연결 리스트의 마지막까지 도달하는 데 next를 너무 많이 사용해야 하기 때문입니다.
그리고 연결 리스트의 마지막 노드는 유일하게 next 포인터가 null을 가리키기 때문에, 아래 코드와 같이 addLast 메소드를 작성할 수 있습니다.
1
2
3
4
5
6
public void addLast(E obj){
Node<E> tmp = head;
while(tmp.next != null)
tmp=tmp.next
tmp.next=node;
}
문제 1. 경계 조건
head가 비어있다면 어떻게 될까요?
이 경우 tmp가 null이 되고, tmp.next를 찾지 못하는 `NullPointerException` 에러가 발생합니다. 이 문제를 해결하기 위해 아래와 같이 addFirst 메소드처럼 노드를 추가합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public void addLast(E obj){
Node<E> node = new Node<E>(obj);
if (head == null){ // head가 비어있는 경우
head=node;
currentsize++;
return;
}
Node<E> tmp = head;
while(tmp.next != null)
tmp=tmp.next
tmp.next=node;
currentsize++;
}
문제 2. 시간 복잡도
연결 리스트의 마지막 노드를 찾을 때 리스트의 맨 앞부터 시작해서 마지막 요소까지 살펴보면 시간 복잡도는 O(n) 입니다. 하지만 `tail` 포인터를 사용하면 이 시간 복잡도를 O(1) 로 만들 수 있습니다.
리스트의 마지막을 가리키는 tail 포인터를 head, currentSize와 같은 전역 변수로 설정하고, 아래와 같이 tail 포인터를 추가하면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
public void addLast(E obj){
Node<E> node = new Node<E>(obj);
if (head == null){
head=node;
tail=node; // head 포인터뿐만 아니라 tail 포인터도 변경
currentsize++;
return;
}
tail.next=node;
tail = node;
currentsize++;
}
removeFirst 메소드
연결 리스트의 첫 node를 제거하는 removeFirst 메소드를 살펴보겠습니다.

보통의 경우, head = head.next를 하면 head가 다음 노드를 가리키게 되고 첫 번째 노드가 제거됩니다. 하지만 다음과 같은 경계 조건에서 에러가 발생하므로 코드를 추가해야 합니다.
경계 조건 1. 자료 구조가 비어있는 경우
head가 null을 가리키는 경우입니다. 이 때, head가 head.next를 가리키게 하면 NullPointerException 에러가 발생하게 됩니다. 그래서 head가 null을 가르키는 경우, 아무것도 하지 않고 `null`을 반환하면 됩니다.
경계 조건 2. 자료 구조에 단 하나의 요소가 들어있을 때

head 포인터, tail 포인터 모두 null을 가리키게 해야 합니다.
코드를 작성하면 다음과 같습니다.(경계 조건 2의 상황에서 head.next == null 을 사용할 경우 NullPointException이 발생할 수 있으므로 주의가 필요합니다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public E removefirst(){
// 경계 조건 1
if (head == null)
return null;
E tmp = head.data;
// 경계 조건 2
if (head == tail) // head.next == null, currentSize == 1도 가능
head = null;
tail = null;
// 그 외의 경우
else
head = head.next;
currentSize--;
return tmp;
}
removeLast 메소드
연결 리스트의 마지막 node를 제거하는 removeLast 메소드입니다.

마지막 노드를 마지막에서 2번째 노드로 옮겨 연결리스트의 마지막 노드를 제거합니다. 단일 연결 리스트이기 때문에 2번째 노드를 찾으려면 head에서부터 시작해야 합니다.
임시 포인터 `current`와 `previous`를 활용하여 마지막에서 2번째 노드를 찾을 수 있습니다.

current는 현재 위치를 가리키는 포인터이고 previous는 이전 위치를 가리키는 포인터입니다. current 포인터가 tail과 같으면 previous 포인터는 마지막에서 2번째 노드를 가리키게 됩니다.
이번에도 경계 조건에서 에러가 발생하므로 코드를 추가해야 합니다. 자료 구조가 비어있는 경우와 자료 구조에 단 하나의 요소가 들어있을 때 removeFirst에서와 똑같이 예외 처리를 해주면 됩니다.
코드를 작성하면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public E removeLast(){
// 자료 구조가 비어있는 경우
if (head == null)
return null;
// 하나의 요소만 들어있는 경우(removeFirst와 동일)
if (head == tail)
return removeFirst();
// 그 외의 경우
// 임시 포인터 current, previous를 활용하여 마지막 노드를 제거합니다.
Node<E> current = head, previous = null;
while (current != tail) {
previous = current;
current = current.next;
}
previous.next = null;
// tail을 업데이트하지 않을 경우 연결 리스트가 2개로 나뉨
tail = previous;
currentSize--;
return current.data;
}
remove와 find
임의의 위치의 노드를 제거하는 remove와 노드를 찾는 find에 대해 살펴보겠습니다.
우선 특정 위치의 노드를 제거하기 위해 요소의 위치를 파악해야 하고, 그 요소가 제거하고자 하는 요소가 맞는지 확인을 해야 합니다.
Comparable 인터페이스를 사용하여 노드를 찾겠습니다.

if (((Comparable) current.data).compareTo(obj) == 0) 조건이 참인 경우 원하는 노드를 찾을 수 있습니다.
찾은 노드를 제거하기 위해서는 바로 앞 노드의 next 포인터가 다음 노드를 가리키게 만들면 됩니다. previous, current의 2가지 포인터를 사용하여 각각 바로 앞의 노드와 제거하고자 하는 노드를 가리키게 할 수 있습니다.
이제 경계 조건을 고려하여 메소드를 완성시키도록 하겠습니다.
노드가 1개만 있는 경우, 첫 번째 노드를 제거하는 경우에는 removeFirst 메소드를 사용합니다. 그리고 마지막 요소를 제거하는 경우에는 removeLast 메소드를 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public E remove(E obj){
Node<E> current = head, previous = null;
while(current != null) {
// 1. find
if (((Comparable<E>) current.data).compareTo(obj) == 0) {
if (current==head) // 노드가 1개 or 첫 번째 노드 제거
return removeFirst();
if (current==tail) // 마지막 노드 제거
return removeLast();
currentsize--;
previous.next = current.next; // 2. remove
return current.data;
}
// 찾고자 하는 요소가 아니면
previous = current;
current = current.next;
}
return null; // 찾지 못한 경우
}
주의해야 할 사항이 있습니다.
우선 반복문을 통해 null인지 확인하고 있는 값이 current.next가 아닌 current라는 것 입니다. current.next가 null일 때 멈추게 되면 마지막 요소를 확인하지 못하기 때문입니다. removeLast 메소드와는 다른 부분입니다.
또한, 반환하는 값이 매개변수로 전달받은 obj가 아닌 current.data라는 점 입니다. 다른 자료 구조를 사용할 때에도 적용되는 부분인데, 객체의 특정 정보를 통해 다른 정보를 알 수 있기 때문입니다. 예를 들어, 학생이라는 클래스에 학번이라는 변수가 있다면, compareTo메소드를 통해 이 정보가 일치하는지를 판단하고, 다른 정보들을 반환할 수 있게 됩니다. 다양한 상황에서 이런 정보를 필요로 할 수 있기에 remove 메소드에 어떠한 객체가 들어왔을 때, 그 객체를 반환하면 안되고 그 안에 들어있는 것을 반환해야 합니다.
이번에는 노드를 찾는 메소드를 구현해보겠습니다.
마찬가지로 compareTo 메소드를 사용해서 확인하고자 하는 객체가 리스트에 들어있는지 알 수 있습니다. 그리고 존재한다면 true를 반환하도록 boolean 타입의 메소드를 구현하겠습니다.
1
2
3
4
5
6
7
8
9
public boolean contains(E obj){
Node<E> current = head;
while(current != null) {
if (((Comparable<E>) obj).compareTo(current.data) == 0)
return true;
current = current.next;
}
return false;
}
peak 메소드
특정한 요소의 내용을 읽는 peek라는 메소드들에 대해 알아보겠습니다.
peekFirst()는 아래와 같이 구현할 수 있습니다. 리스트가 비어있으면 NullPointerException 에러가 발생하기 때문에 따로 처리해줍니다.
1
2
3
4
5
public E peekFirst(){
if (head == null)
return null;
return head.data;
}
peekLast() 메소드는 임시 포인터를 활용하여 작성할 수 있습니다. 하나씩 값을 확인하기 때문에 시간 복잡도는 O(n)이 나오게 됩니다.
1
2
3
4
5
public E peakLast(){
while (tmp.next != null) // tmp != null은 마지막 요소를 지나
tmp = tmp.next
return tmp.data;
}
하지만 tail 포인터를 활용한다면 시간 복잡도가 1이 나오도록 구현할 수 있습니다.
1
2
3
4
5
public E peekLast(){
if (tail == null)
return null;
return tail.data;
}
연결 리스트 테스트
연결 리스트의 메소드를 테스트하는 방법을 알아보겠습니다.
연결리스트를 직접 만들어 지금까지 배운 메소드를 테스트할 수 있습니다. ListI 인터페이스를 구현한 LinkedList를 테스트하는 방법은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Tester {
public static void main (String[] args){
static ListI<Integer> List = new LinkedList <Integer>();
int n = 10;
// 연결 리스트를 만듭니다.
for(int i = 0; i < n; i++)
list.addFirst(i); // addLast도 가능
// 연결 리스트를 제거합니다.
for(int i = n-1; i >= 0; i--)
int x = list.removeFirst();
if (x != i) ...
for(int i = 0; i < n; i++)
int x = list.removeLast();
}
ListI를 사용한 이유는, ListI 인터페이스를 구현한 다른 클래스 역시 테스트할 수 있기 때문입니다. 예를 들면, new LinkedList <Integer>(); 대신 new ArrayBasedList<Integer>();를 테스트할 수 있습니다.
addFirst() 메소드가 동작하는 과정은 아래와 같습니다.
 –>
–>  –>
–>
리스트는 뒤로 갈수록 값이 작아집니다.
이렇게 새로운 클래스를 작성하여 정수를 활용하는 것 만으로도 연결 리스트 메소드를 간단하게 테스트 할 수 있습니다.
(참고로 추가하고 제거한 뒤에는 currentSize 값이 맞는지 확인해야 합니다.)
반복자
연결 리스트 코드를 완성하기 위해 반복자를 작성해야 합니다. 반복자 인터페이스에는 Iterator와 Iterable이 있습니다.
배열의 각각의 원소를 출력할 때, 다음과 같이 코드를 작성합니다.
1
2
3
4
int arr[] = {1,2,3,4,5};
for (int i=0; i<arr.length; i++){
system.out.println(arr[i]);
}
위와 같은 코드는 자주 사용하기 때문에 반복자가 만들어졌습니다.
그래서 Iterable을 구현한 자료 구조 클래스가 있으면, 아래와 같이 간단히 표현할 수 있습니다.
1
2
3
4
int arr[] = {1,2,3,4,5};
for (int x : arr){
system.out.println(x);
}
하지만 객체에서 두 번째 방식으로 반복문이 동작하도록 하기 위해서는 Iterator 인터페이스를 구현해야 합니다.
참고사항 jdk 1.8버전으로 변경되면서 반복자 인터페이스에도 영향이 미쳤고, 그에 따라 구현 방법도 달라졌습니다. 두 가지 변경사항을 살펴보겠습니다.
두 번째로 인터페이스에 기본 메소드(default)를 구현할 수 있게 되었습니다. 기본 메소드로 구현할 수 없는 메소드는 hashCode(), equals(), toString()(이 메소드들의 기본 구현은 Object에 있기 때문 ) 입니다.
Iterator 인터페이스에는 remove라는 메소드가 정의되어 있습니다. 그리고 자바 1.8의 기본 구현은 throw new UnsupportedOperationException을 발생시킵니다.
1
2
3
public void remove() {
throw new UnsupportedOperationException();
}
자바 1.8을 사용하는 경우 위의 remove() 메소드는 신경쓸 필요가 없습니다.
두 번째 병견사항으로는 반복자 인터페이스에 forEachRemaining() 메소드로, 이 역시 자바 1.8을 사용할 경우 고려할 필요가 없는 메소드입니다.
이제 Iterator 인터페이스를 구현하는 코드를 확인하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public Iterator<E> iterator(){
return new IteratorHelper();
}
public class LinkedList<E> implements ListI<E>{
class IteratorHelper implement Iterator<E>{
Node<E> index; // 용도가 다른 변수이기에 새로운 이름 사용
public IteratorHelper(){
index = head;
}
public boolean hasNext(){ // 포인터가 null을 가리키는지
return (index != null)
}
public E next(){
if (!hasNext())
throw new NoSuchElementException();
E val = index.data;
index = index.next;
return val;
}
}
}
위의 코드를 LinkedList 클래스 안에 넣으면 앞에서 사용했던 간소화 된 반복문을 사용할 수 있게 됩니다.
이중 연결 리스트
기존에 만들어봤던 단일 연결 리스트는 tail 포인터가 있더라도 removeLast를 하기 위한 시간 복잡도는 항상 O(n)입니다. 마지막 요소부터 앞으로 넘어갈 방법이 없기 때문이죠. 무조건 첫 요소부터 시작한 뒤 하나씩 뒤로 넘어가서 마지막 요소의 전까지 와야지만 마지막 요소를 제거할 수 있었습니다.
이러한 상황을 더 빨리 해결하기 위한 방법으로 단일 연결 리스트에 previous 포인터를 추가한 이중 연결 리스트에 대해 살펴보도록 하겠습니다.
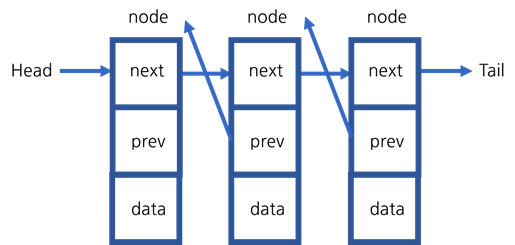
위와 같이 단일 연결 리스트에 바로 전의 노드를 가리키는 previous 포인터를 추가하게 되면, removeLast 메소드를 사용할 때 tail 포인터만 찾은 뒤 노드의 data를 tmp에 저장하면 됩니다.
1
2
3
4
E tmp = tail.data;
tail.prev.next = null;
tail = tail.prev;
return tmp;
즉, 이중 연결 리스트는 tail 포인터가 가리키는 노드에서 previous 포인터가 가리키는 노드를 찾기 때문에 시간 복잡도가 O(1)이 됩니다.
이중 연결 리스트의 단점은 tail 포인터를 했을 때와 비슷하게, previous 포인터가 추가되기 때문에 노드를 추가하는 과정이 더 복잡해진다는 것입니다.
원형 연결 리스트
 or
or 
원형 연결 리스트는 그림과 같이 마지막 next 포인터가 연결 리스트의 노드를 가리키는 연결 리스트입니다.
원형 연결 리스트의 마지막 next 포인터가 head를 가리킬 수도 있고, 연결 리스트 내의 다른 노드를 가리킬 수도 있습니다.
head를 가리키는지 확인하는 방법은 다음과 같습니다.
- head에서 시작하여
t == null이 될 때까지 반복한다면, 시간복잡도는 O(n) 입니다. tail포인터를 사용할 경우, 시간복잡도는 O(1) 입니다.
마지막 next 포인터가 임의의 노드를 가리킨다면(tail.next != null이라면) 확인하는 방법은 다음과 같습니다.
tail에서 시작하여tail포인터가 다시 나타나는지 확인합니다. 시간복잡도는 O(n) 입니다.tail포인터가 없다면, 임시 포인터 2개를 사용하여 시작점을 잡고currentSize만큼 떨어진 노드까지 확인한 후 시작점을 다음으로 옮겨 같은 노드가 나타날 때까지 반복합니다. 시간복잡도는 O(n^2) 입니다.
스택과 큐
스택과 큐에 대해 알아볼텐데, 우선 기본적인 배열을 살펴보겠습니다.
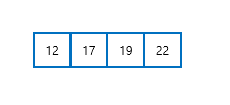 위와 같이 정수형 요소를 갖는 배열이 있을 때,
위와 같이 정수형 요소를 갖는 배열이 있을 때, addLast()와 removeLast() 메서드는 상수 시간 O(1)의 복잡도를 가집니다. 반면, 맨 앞에 요소를 추가하거나 제거하고자 한다면 요소들을 하나씩 뒤로 옮겨야 하고 시간 복잡도는 O(n) 입니다.
| Array | complexity |
|---|---|
| addLast removeLast |
O(1) |
| addFirst removeFirst |
O(n) |
기본적인 배열로 스택과 큐를 구현하는 것은 비효율적이기에 사용하지 않습니다.
펄이나 파이썬 같은 언어에서는 배열을 선언하지 않고 사용할 수 있고, 양쪽 끝에 추가하거나 제거할 때 상수 시간이 보장됩니다. 배열이 비어있거나 꽉 찼을 때 head와 tail이 같은 곳을 가리키는 원형 자료 구조를 선택했기 때문입니다. 물론 이 작업을 위해 원래의 크기보다 더 큰 배열이 필요합니다.
연결 리스트에서는 배열 맨 앞을 가리키는 head 포인터를 사용합니다. 그래서 리스트의 첫 부분을 제거하거나 추가하는 과정의 시간 복잡도가 상수입니다. 더 효율적인 알고리즘인 연결 리스트는 스택과 큐를 하는 데 사용합니다.
배열은 연결 리스트보다 전형적으로 빠르고 메모리도 덜 차지합니다. 그러나 배열은 크기가 정해져 있습니다.
| 장점 | 단점 | |
|---|---|---|
| Arrays | 빠르다 메모리를 적게 차지한다 |
크기가 고정되어 있다 추가하는 작업의 비용이 크다(시간이 오래 걸린다) |
| LinkedLists | 크기가 정해져 있지 않다. | 느리고, 메모리가 많이 필요하다 |
마치며
이렇게 연결 리스트에 대해 공부를 했습니다.
기본적인 원리부터, 세부 메소드들을 차근차근 구현해보며 연결 리스트에 대해 이해할 수 있었고, 어떠한 상황에서 사용될 수 있는지 알아보는 시간이었습니다.
많은 내용을 다룬 것 같지만, 각 내용을 간략히 정리했기에 다시 공부가 필요할 때에는 목차를 통해 필요한 내용을 빠르게 확인하면 될 것 같습니다.
다음 강의는 해시에 대한 내용입니다.

댓글남기기